


4.2 Sorting and Searching
The sorting problem is to rearrange a set of items in ascending order. One reason that it is so useful is that it is much easier to search for something in a sorted list than an unsorted one. In this section, we will consider in detail two classical algorithms for sorting and searching, along with several applications where their efficiency plays a critical role.
Binary Search
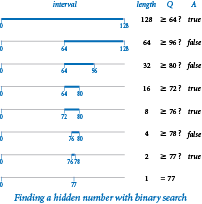
In the game of "twenty questions", your task is to guess the value of a hidden number that is one of the n integers between 0 and n-1. (For simplicity, we will assume that n is a power of two.) Each time that you make a guess, you are told whether your guess is too high or too low. An effective strategy is to maintain an interval [lo, hi) that contains the hidden number, guess the number in the middle of the interval, and then use the answer to halve the interval size. The program questions.py implements this strategy, which is an example of the general problem-solving method known as binary search.
Correctness proof.
First, we have to convince ourselves that the approach is correct: that it always leads us to the hidden number. We do so by establishing the following facts:- The interval always contains the hidden number.
- The interval sizes are the powers of two, decreasing from n.
The first of these facts is enforced by the code; the second follows by noting that if the interval size (hi-lo) is a power of two, then the next interval size is (hi-lo)/2, which is the next smaller power of two. These facts are the basis of an induction proof that the method operates as intended. Eventually, the interval size becomes 1, so we are guaranteed to find the number.
Running time analysis.
Since the size of the interval decreases by a factor of 2 at each iteration (and the base case is reached when n = 1), the running time of binary search is lg n.Linear-logarithm chasm.
The alternative to using binary search is to guess 0, then 1, then 2, then 3, and so forth, until hitting the hidden number. We refer to such an algorithm as a brute-force algorithm: it seems to get the job done, but without much regard to the cost (which might prevent it from actually getting the job done for large problems). In this case, the running time of the brute-force algorithm is sensitive to the input value, but could be as much as n and has expected value n/2 if the input value is chosen at random. Meanwhile, binary search is guaranteed to use no more than lg n steps.Binary representation.
If you look back to binary.py, you will recognize that binary search is nearly the same computation as converting a number to binary! Each guess determines one bit of the answer. In our example, the information that the number is between 0 and 127 says that the number of bits in its binary representation is 7, the answer to the first question (is the number greater than or equal to 64?) tells us the value of the leading bit, the answer to the second question tells us the value of the next bit, and so forth. For example, if the number is 77, the sequence of answers true false, false, true, true, false, true immediately yields 1001101, the binary representation of 77.Inverting a function.
As an example of the utility of binary search in scientific computing, we revisit a problem that we first encountered in the exercises in Section 2.1: inverting an increasing function. Given an increasing function f and a value y, and an open interval [lo, hi), our task is to find a value x within the interval such that f(x) = y. In this situation, we use real numbers as the endpoints of our interval, not integers, but we use the same essential approach that we used for guessing a hidden integer with the "twenty questions" problem: we halve the length of the interval at each step, keeping x in the interval, until the interval is sufficiently small that we know the value of x to within a desired precision), which we take as an argument to the function. This figure illustrates the first step.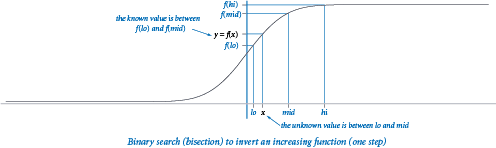
The program bisection.py implements this strategy. We start with an interval (lo, hi) known to contain x and use the following recursive procedure:
- Compute mid = (hi + lo) / 2.
- Base case: If hi - lo is less than δ, then return mid as an estimate of x.
- Recursive step: Otherwise, test whether f(mid) > y. If so, look for x in (lo, mid); if not, look for x in (mid, hi).
The key to this approach is the idea that the function is increasing — for any values a and b, knowing that f(a) < f(b) tells us that a < b, and vice versa. In this context, binary search is often called bisection search because we bisect the interval at each stage.
Binary search in a sorted array.
During much of the last century people would use a publication known as a dictionary to look up the definition of a word. Entries appears in order, sorted by a key that identifies it (the word). Think about how you would look up a word in a dictionary. A brute-force solution would be to start at the beginning, examine each entry one at a time, and continue until you find the word. No one uses that approach: instead, you open the dictionary to some interior page and look for the word on that page. If it is there, you are done; otherwise, you eliminate either the part of the dictionary before the current page or the part of the dictionary after the current page from consideration and repeat.Exception filter.
We now use binary search to solve the existence problem: is a given key in a sorted database of keys? For example, when checking the spelling of a word, you need only know whether your word is in the dictionary and are not interested in the definition. In a computer search, we keep the information in an array, sorted in order of the key. The binary search code in binarysearch.py differs from our other applications in two details. First, the array length n need not be a power of two. Second, it has to allow the possibility that the item sought is not in the array. The client program implements an exception filter: it reads a sorted list of strings from a file which we refer to as the whitelist (for example, white.txt) and an arbitrary sequence of strings from standard input (for example, emails.txt) and writes those in the sequence that are not in the whitelist.Insertion Sort
Binary search requires that the array be sorted, and sorting has many other direct applications, so we now turn to sorting algorithms. We consider first a brute-force algorithm, then a sophisticated algorithm that we can use for huge arrays.
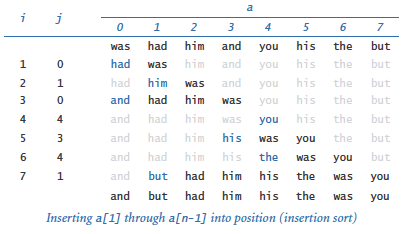
The brute-force algorithm we consider is known as insertion sort. It is based on a simple approach that people often use to arrange hands of playing cards — that is, consider the cards one at a time and insert each into its proper place among those already considered (keeping them sorted).
The program insertion.py contains an implementation of a sort() function that mimics this process to sort elements in an array a[] of length n. The test client reads all the strings from standard input, puts them into the array, calls the sort() function to sort them, and then writes the sorted result to standard output. Try running it to sort the small tiny.txt file. Also try running it to sort the much larger tomsawyer.txt file, but be prepared to wait a long time!
The outer loop sorts the first i entries in the array; the inner loop can complete the sort by putting a[i] into its proper position in the array.
Mathematical analysis.
Thesort() function contains a while loop nested inside a for loop, which suggests that the running time is quadratic. However, we cannot immediately draw this conclusion because the while loop terminates as soon as a[j] is greater than or equal to a[j-1].
- Best case. When the input array is already in sorted order, the inner loop amounts to nothing more than a comparison (to learn that
a[j-1]is less than or equal toa[j]), so the total running time is linear. - Worst case. When the input is reverse sorted, the inner loop does not terminate until j equals 0. So, the frequency of execution of the instructions in the inner loop is 1 + 2 + ... + n-1 ~ n2/2.
- Average case. When the input is randomly ordered, we expect that each new element to be inserted is equally likely to fall into any position, so that element will move halfway to the left on average. Thus, we expect the running time to be 1/2 + 2/2 + ... + (n-1)/2 ~ n2/2.
Empirical analysis.
Program timesort.py implements a doubling test for sorting functions. We can use it to confirm our hypothesis that insertion sort is quadratic for randomly ordered files:
% python >>> import insertion >>> import timesort >>> timesort.doublingTest(insertion.sort, 128, 100) 128 3.67 256 3.73 512 4.21 1024 4.19 2048 4.11
Sensitivity to input.
Note that thedoublingTest() function in timesort.py takes parameter m and runs m experiments for each array size, not just one. One reason for doing so is that the running time of insertion sort is sensitive to its input values. It is not correct to flatly predict that the running time of insertion sort will be quadratic, because your application might involve input for which the running time is linear.
Comparable keys.
We want to be able to sort any type of data that has a natural order. Happily, our insertion sort and binary search functions work not only with strings but also with any data type that is comparable. You can make a user-defined type comparable by implementing the six special methods corresponding to the==, !=, <, <=, >, and >= operators. In fact, our insertion sort and binary search functions rely on only the < operator, but it is better style to implement all six special methods.
Mergesort

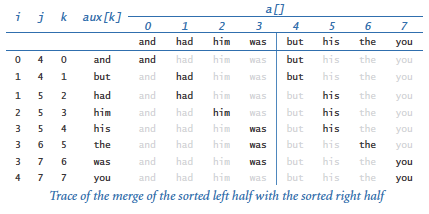
To develop a faster sorting algorithm, we use a divide-and-conquer approach to algorithm design that every programmer needs to understand. This nomenclature refers to the idea that one way to solve a problem is to divide it into independent parts, conquer them independently, and then use the solutions for the parts to develop a solution for the full problem. To sort an array with this strategy, we divide it into two halves, sort the two halves independently, and then merge the results to sort the full array. This method is known as mergesort.To sort a[lo, hi), we use the following recursive strategy:
- Base case: If the subarray size is 0 or 1, it is already sorted.
- Recursive step: Otherwise, compute mid = (hi + lo)/2, sort (recursively) the two subarrays a[lo, mid) and a[mid, hi), and merge them.
The program merge.py is an implementation. As with insert.py, the test client reads all the strings from standard input, puts them into the array, calls the sort() function to sort them, and then writes the sorted result to standard output. Try running it to sort the small tiny.txt file and the much larger tomsawyer.txt file.
As usual, the easiest way to understand the merge process is to study a trace of the contents of the array during the merge.
Mathematical analysis.
 The inner loop of mergesort is centered on the auxiliary array. The
The inner loop of mergesort is centered on the auxiliary array. The for loop involves n iterations, so the frequency of execution of the instructions in the inner loop is proportional to the sum of the subarray lengths over all calls to the recursive function. The value of this quantity emerges when we arrange the calls on levels according to their size. For simplicity, suppose that n is a power of 2, with n = 2k. On the first level, we have one call for size n; on the second level, we have two calls for size n/2; on the third level, we have four calls for size n/4; and so forth, down to the last level with n/2 calls of size 2. There are precisely k = lg n levels, giving the grand total n lg n for the frequency of execution of the instructions in the inner loop of mergesort. This equation justifies a hypothesis that the running time of mergesort is linearithmic.
When n is not a power of 2, the subarrays on each level are not necessarily all the same size, but the number of levels is still logarithmic, so the linearithmic hypothesis is justified for all n.
Empirical analysis.
We can run program timesort.py to perform a doubling test to confirm our hypothesis that mergesort has running time n lg n for randomly ordered files:
% python >>> import merge >>> import timesort >>> timesort.doublingTest(merge.sort, 128, 100) 128 1.84 256 2.15 512 2.22 1024 2.17 2048 2.13 4096 2.12 8192 2.14
Quadratic-linearithmic chasm.
The difference between n2 and n lg n makes a huge difference in practical applications. Understanding the enormousness of this difference is another critical step to understanding the importance of the design and analysis of algorithms. For a great many important computational problems, a speedup from quadratic to linearithmic makes the difference between being able to solve a problem involving a huge amount of data and not being able to effectively address it at all.Python System Sort
Python includes two operations for sorting. The method sort() in the built-in list data type rearranges the items in the underlying list into ascending order, much like merge.sort(). In contrast, the built-in function sorted() leaves the underlying list alone; instead, it returns a new list containing the items in ascending order. This interactive Python script at right illustrates both techniques.
The Python system sort uses a version of mergesort. It is likely to be substantially faster (10-20×) than merge.py because it uses a low-level implementation that is not composed in Python, thereby avoiding the substantial overhead that Python imposes on itself. As with our sorting implementations, you can use the system sort with any comparable data type, such as Python's built-in str, int, and float data types.
Application: Frequency Counts
The program frequencycount.py reads a sequence of strings from standard input and then writes a table of the distinct values found and the number of times each was found, in decreasing order of the frequencies. We accomplish this by two sorts.
Computing the frequencies.
Our first step is to sort the strings on standard input. In this case, we are not so much interested in the fact that the strings are put into sorted order, but in the fact that sorting brings equal strings together. If the input is
then the result of the sort is
with equal strings like the three occurrences of to brought together in the array. Now, with equal strings all together in the array, we can make a single pass through the array to compute all the frequencies. The Counter class, as defined in counter.py from Section 3.3, is the perfect tool for the job.
Sorting the frequencies.
Next, we sort theCounter objects by frequency. We can do so in client code by augmenting the Counter data type to include the six comparison methods for comparing Counter objects by their count. Thus, we simply sort the array of Counter objects to rearrange them in ascending order of frequency! Next, we reverse the array so that the elements are in descending order of frequency. Finally, we write each Counter object to standard output.
Zipf's law.
The application highlighted in frequencycount.py is elementary linguistic analysis: which words appear most frequently in a text? A phenomenon known as Zipf's law says that the frequency of the ith most frequent word in a text of m distinct words is proportional to 1/i. Try running frequencycount.py on the large leipzig100k.txt, leipzig200k.txt, and leipzig1m.txt files to observe that phenomenon.Q & A
Q. Why do we need to go to such lengths to prove a program correct?
A. To spare ourselves considerable pain. Binary search is a notable example. For example, you now understand binary search; a classic programming exercise is to compose a version that uses a while loop instead of recursion. Try solving the first three exercises in this section without looking back at the code in the book. In a famous experiment, Jon Bentley once asked several professional programmers to do so, and most of their solutions were not correct.
Q. Why introduce the mergesort algorithm when Python provides an efficient sort() method defined in the list data type?
A. As with many topics we have studied, you will be able to use such tools more effectively if you understand the background behind them.
Q. What is the running time of the following version of insertion sort on an array that is already sorted?
def sort(a): n = len(a) for i in range(1, n): for j in range(i, 0, -1): if a[j] < a[j-1]: exchange(a, j, j-1) else: break
A. Quadratic time in Python 2; linear time in Python 3. The reason is that, in Python 2, range() is a function that returns an array of integers of length equal to the length of the range (which can be wasteful if the loop terminates early because of a break or return statement). In Python 3, range() returns an iterator, which generates only as many integers as needed.
Q. What happens if I try to sort an array of elements that are not all of the same type?
A. If the elements are of compatible types (such as int and float), everything works fine. For example, mixed numeric types are compared according to their numeric value, so 0 and 0.0 are treated as equal. If the elements are of incompatible types (such as str and int), then Python 3 raises a TypeError at run time. Python 2 supports some mixed-type comparisons, using the name of the class to determine which object is smaller. For example, Python 2 treats all integers as less than all strings because 'int' is lexicographically less than 'str'.
Q. Which order is used when comparing strings with operators such as == and <?
A. Informally, Python uses lexicographic order to compare two strings, as words in a book index or dictionary. For example 'hello' and 'hello' are equal, 'hello' and 'goodbye' are unequal, and 'goodbye' is less than 'hello'. More formally, Python first compares the first character of each string. If those characters differ, then the strings as a whole compare as those two characters compare. Otherwise, Python compares the second character of each string. If those characters differ, then the strings as a whole compare as those two characters compare. Continuing in this manner, if Python reaches the ends of the two strings simultaneously, then it considers them to be equal. Otherwise, it considers the shorter string to be the smaller one. Python uses Unicode for character-by-character comparisons. We list a few of the most important properties:
'0'is less than'1', and so forth.'A'is less than'B', and so forth.'a'is less than'b', and so forth.- Decimal digits (
'0'to'9') are less than the uppercase letters ('A'to'Z'). - Uppercase letters (
'A'to'Z') are less than lowercase letters ('a'to'z').
Exercises
-
Develop an implementation of questions.py that takes the maximum number
nas command-line argument (it need not be a power of 2). Prove that your implementation is correct. -
Compose a nonrecursive version of binarysearch.py.
-
Modify binarysearch.py so that if the search key is in the array, it returns the smallest index
ifor whicha[i]is equal tokey, and otherwise it returns the largest indexifor whicha[i]is smaller thankey(or-1if no such index exists). -
Describe what happens if you apply binary search to an unordered array. Why shouldn't you check whether the array is sorted before each call to binary search? Could you check that the elements binary search examines are in ascending order?
-
Describe why it is desirable to use immutable keys with binary search.
-
Let f() be a monotonically increasing function with f(a) < 0 and f(b) > 0. Compose a program that computes a value x such that f(x) = 0 (up to a given error tolerance).
-
Add code to insertion.py to produce the trace given above.
-
Add code to merge.py to produce the trace given above.
-
Give traces of insertion sort and mergesort in the style of the traces shown above, for the input
it was the best of times it was. -
Compose a program
dedup.pythat reads strings from standard input and writes them to standard output with all duplicates removed (and in sorted order). -
Compose a version of mergesort, as defined in merge.py, that creates an auxiliary array in each recursive call to
_merge()instead of creating only one auxiliary array insort()and passing it as an argument. What impact does this change have on performance? -
Compose a nonrecursive version of mergesort, as defined in merge.py.
-
Find the frequency distribution of words in your favorite book. Does it obey Zipf's law?
Creative Exercises
The following exercises are intended to give you experience in developing fast solutions to typical problems. Think about using binary search, mergesort, or devising your own divide-and-conquer algorithm. Implement and test your algorithm.
-
Median. Study the function
median()instdstats.py. It computes the median of a given array of numbers in linearithmic time. Note that it works by reducing the problem to sorting. -
Mode. Add to
stdstats.pya functionmode()that computes in linearithmic time the mode (value that occurs most frequently) of a sequence of n integers. Hint: Reduce to sorting. -
Integer sort. Compose a linear-time filter reads from standard input a sequence of integers that are between 0 and 99 and writes the integers in sorted order on standard output. For example, presented with the input sequence
98 2 3 1 0 0 0 3 98 98 2 2 2 0 0 0 2
your program should write the output sequence
0 0 0 0 0 0 1 2 2 2 2 2 3 3 98 98 98
-
Floor and ceiling. Given a sorted array of n comparable keys, compose functions
floor()andceiling()that returns the index of the largest (or smallest) key not larger (or smaller) than an argument key in logarithmic time. -
Bitonic maximum. An array is bitonic if it consists of an increasing sequence of keys followed immediately by a decreasing sequence of keys. Given a bitonic array, design a logarithmic algorithm to find the index of a maximum key.
-
Search in a bitonic array. Given a bitonic array of n distinct integers, design a logarithmic-time algorithm to determine whether a given integer is in the array.
-
Closest pair. Given an array of n floats, compose a function to find in linearithmic time the pair of floats that are closest in value.
-
Furthest pair. Given an array of n floats, compose a function to find in linear time the pair of integers that are farthest apart in value.
Two sum. Compose a function that takes as argument an array of n integers and determines in linearithmic time whether any two of them sum to 0.
-
Three sum. Compose a function that takes as argument an array of n integers and determines whether any three of them sum to 0. Your program should run in time proportional to n2 log n. Extra credit: Develop a program that solves the problem in quadratic time.
-
Majority. Given an array of n elements, an element is a majority if it appears more than n/2 times. Compose a function that takes an array of n strings as an argument and identifies a majority (if it exists) in linear time.
-
Common element. Compose a function that takes as argument three arrays of strings, determines whether there is any string common to all three arrays, and if so, returns one such string. The running time of your function should be linearithmic in the total number of strings.
-
Largest empty interval. Given n timestamps for when a file is requested from web server, find the largest interval of time in which no file is requested. Compose a program to solve this problem in linearithmic time.
-
Prefix-free codes. In data compression, a set of strings is prefix-free if no string is a prefix of another. For example, the set of strings
01,10,0010, and1111is prefix-free, but the set of strings01,10,0010,1010is not prefix-free because10is a prefix of1010. Compose a program that reads in a set of strings from standard input and determines whether the set is prefix-free. -
Partitioning. Compose a function that sorts an array that is known to have at most two different values. Hint: Maintain two pointers, one starting at the left end and moving right, the other starting at the right end and moving left. Maintain the invariant that all elements to the left of the left pointer are equal to the smaller of the two values and all elements to the right of the right pointer are equal to the larger of the two values.
-
Dutch national flag. Compose a function that sorts an array that is known to have at most three different values. (Edsgar Dijkstra named this the Dutch-national-flag problem because the result is three "stripes" of values like the three stripes in the flag.) Hint: Reduce to the previous problem, by first partitioning the array into two parts with all elements having the smallest value in the first part and all other elements in the second part, then partition the second part.
-
Quicksort. Compose a recursive program that sorts an array of randomly ordered distinct elements. Hint: Use a method like the one described in the previous exercise. First, partition the array into a left part with all elements less than v, followed by v, followed by a right part with all elements greater than v. Then, recursively sort the two parts. Extra credit: Modify your method (if necessary) to work properly when the elements are not necessarily distinct.
-
Reverse domain. Compose a program to read in a list of domain names from standard input and write the reverse domain names in sorted order. For example, the reverse domain of
cs.princeton.eduisedu.princeton.cs. This computation is useful for web log analysis. To do so, create a data typeDomainthat implements the special comparison methods, using reverse domain name order. -
Local minimum in an array. Given an array of n floats, compose a function to find in logarithmic time a local minimum (an index
isuch thata[i] < a[i-1]anda[i] < a[i+1]). -
Discrete distribution. Design a fast algorithm to repeatedly generate numbers from the discrete distribution. Given an array
p[]of nonnegative floats that sum to 1, the goal is to return indexiwith probabilityp[i]. Form an arrays[]of cumulated sums such thats[i]is the sum of the firstielements ofp[]. Now, generate a random floatrbetween 0 and 1, and use binary search to return the indexifor whichs[i] ≤ r < s[i+1]. -
Rhyming words. Tabulate a list that you can use to find words that rhyme. Use the following approach:
- Read in a dictionary of words into an array of strings.
- Reverse the letters in each word (
confoundbecomesdnuofnoc, for example). - Sort the resulting array.
- Reverse the letters in each word back to their original order.
For example,
confoundis adjacent to words such asastoundandsurroundin the resulting list.